内置节点 2
加载器
Load Checkpoint
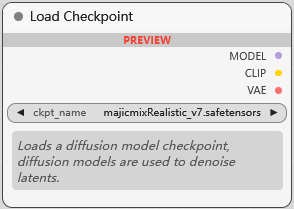
Checkpoint 模型加载器, 用于加载包含了 CLIP, VAE 和 基本模型 的加载器
Load VAE

VAE 模型加载器, 用于加载 VAE 模型加载器
Load LoRA
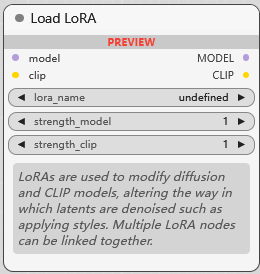
LoRA 模型加载器, 用于加载 Lora 模型, 它的作用是调节 扩散模型(基本模型) 和 CLIP 模型, 让生成结果向 LoRA 靠近. 多个 Lora 可以连接起来. 第 2,3 个参数用于调节基本模型和 CLIP 模型权重
LoraLoaderModelOnly
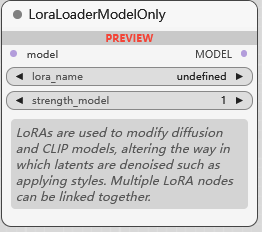
该加载器与上一个不同之处在于, 它只调节 基本模型.
Load ControlNet Model
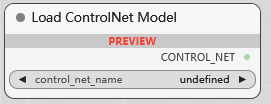
ControlNet 模型加载器.
Load ControlNet Model (diff)
ControlNet 模型加载器的 diff 版本, 与上者不同之处在于需要输入模型.
Load Style Model
风格模型加载器, 加载用于迁移图像风格的模型.
Load CLIP Vision
加载 CLIP 视觉模型, 模型用于图像编码,提取图像的特征 (CLIP 则是文本编码).
unCLIPCheckpointLoader
加载 unCLIP 基本模型的加载器, 这种模型架构同 DALL-E 2, 能生图, 也能对图像进行编辑 (CLIP_VISION 编码图像)
GLIGENLoader
加载 GLIGEN 模型,它通常与 Stable Diffusion 结合使用,增强其对空间位置和属性的控制能力
HypernetworkLoader
加载的是 Hypernetwork 超网络模型, 通常用于微调或修改预训练好的扩散模型,以实现特定风格或概念的学习 (很少用了)
Load Upscale Model
加载放大模型
Image Only Checkpoint Loader (img2vid model)
加载图生视频模型, 例如 SVD, 只能图生视频, 而不能同时添加文本控制
条件节点
CLIP Text Encode (Prompt)

CLIP 文本编码
CLIP Set Last Layer
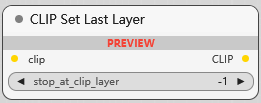
设置 CLIP 停止层, 越深的层级提取的特征越抽象,越偏向于语义信息;而较浅的层级提取的特征则保留了更多的细节信息
ConditioningAverage
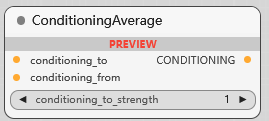
条件平均节点, 用于控制两个输入条件的权重, 1 时是 to 的条件, 0 时是 from 的条件, 0-1 之间两个条件按权重混合
Conditioning (Combine)
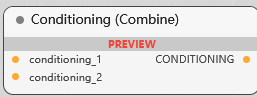
条件合并节点, 将两个条件组合起来
Conditioning (Concat)
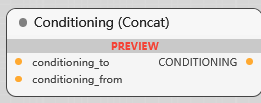
条件连结节点, 将 from 合并到 to 中, 组合成统一的表示
Conditioning (Set Area)

条件设置区域, 将条件限制在指定区域内, 与条件合并使用, 可以很好的控制构图
Conditioning (Set Area with Percentage)

条件设置区域 (按系数), 与前面一个不同之处在于, 这个是按系数控制
ConditioningSetAreaStrength
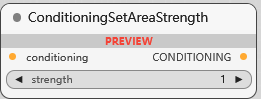
条件设置区域强度控制
Conditioning (Set Mask)
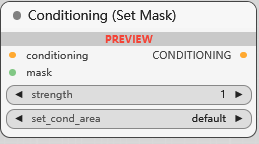
设置遮罩条件, 可调节强度 和 区域(默认或由遮罩本身确定)
CLIP Vision Encode
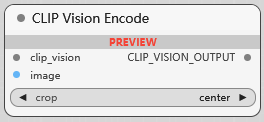
CLIP VISION 编码, 可选对图像裁剪或不裁剪
Apply Style Model
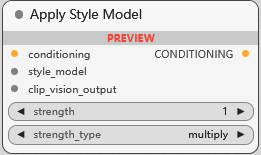
应用风格模型, 将风格模型, 输入调节, 图像特征 统一起来指导扩散模型生成特定风格. 可调节强度, 强度类型只有 multiply (多重)
unCLIPConditioning

unCLIP 模型条件设置, 接收条件和 CLIP VISION 编码的图像, 可调节强度和噪声
Apply ControlNet

应用 ControlNet 模型, 接收正/负调节, ControlNet 模型, 图像, VAE. 可控制强度, 开始/结束时机
SetUnionControlNetType
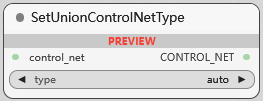
设置 UnionControlNet (包含多种 ControlNet 的模型) 模型的控制类型, 可选:
auto
openpose
depth
hed/pidi/scribble/ted
canny/lineart/anime_lineart/mlsd
normal
segment
tile
repaint
ControlNetInpaintingAliMamaApply

阿里妈妈重绘 ControlNet 应用, 重绘多了 mask 蒙版参数, 控制要重绘的区域
GLIGENTextBoxApply
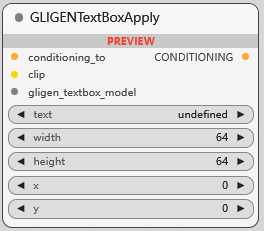
GLIGEN 模型文本控制区域应用, 可指定文本控制的区域
InpaintModelConditioning

重绘模型调节 (用模型对图像进行修复/重绘), 参数 pixels 表示要进行修复的图像的像素数据, noise_mask, 控制噪声是否只在蒙版内产生.
SVD_img2vid_Conditioning
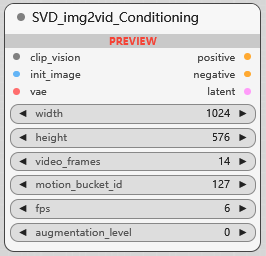
SVD 图生视频条件, 可指定视频宽/高, 视频帧数 video_frames (长度), 视频运动参数 motion_bucket_id , 每秒的帧数 fps, 以及视频增强水平 augmentation_level
LTXVImgToVideo
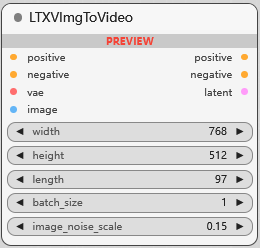
LTXV 模型图生视频条件. length: 生成视频的帧数, batch_size: 一次生成视频数, image_noise_scale: 添加到输入图像的噪声强度
LTXVConditioning
LTXV 模型条件
StableZero123_Conditioning
StableZero123 模型条件, 可指定宽/高, 一次生成数量, 3D 仰角 elevation, 3D 方位角 azimuth
StableZero123_Conditioning_Batched
上一个的批量处理条件, 新增仰角在批量中的增量变化 elevation_batch_increment, 方位角在批量中的增量变化 azimuth_batch_increment 参数
SV3D_Conditioning

SV3D 模型条件, 用于图像生成 3D 视频, 可指定宽/高, 视频帧数, 3D 仰角
SD_4XUpscale_Conditioning

SD_4X 放大条件, 用于图像放大, 可调节放大系数 scale_ratio, 放大过程中噪声增强的水平 noise_augmentation
StableCascade_StageB_Conditioning
StableCascade 模型修改条件, stage_c 在输入条件中加如 Latent 条件
InstructPixToPixConditioning
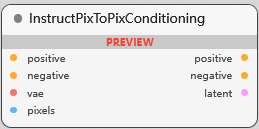
风格转换条件, pixels 原始图像像素数据
潜空间节点
VAE Decode
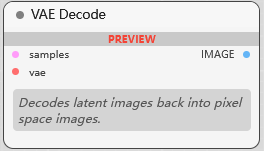
VAE 解码, 潜空间图像到图像
VAE Encode
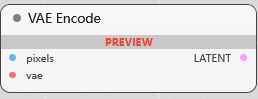
VAE 编码
VAE Encode (for Inpainting)
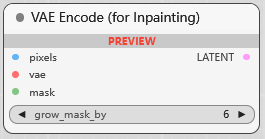
VAE 编码 (重绘), grow_mask_by 调节遮罩重绘影响程度
Set Latent Noise Mask

设置遮罩区域噪声, 罩区域添加额外的噪声来进行局部的重绘
Empty Latent Image
创建空潜空间图像
Upscale Latent

潜空间图像放大, 放大算法:
-
nearest-exact 最近邻精确: 速度最快, 计算最简单。块状效应 (Blockiness), 生成的图像容易出现块状伪影,特别是沿着对角线方向,没有平滑过渡。可以很好地保留尖锐的边缘和细节
-
bilinear 双线性插值: 速度较快, 计算相对简单。比最近邻插值更平滑,块状效应减少。会在一定程度上模糊图像细节,特别是边缘
-
area 区域平均: 速度中等。在缩小图像时,区域平均通常可以产生比其他方法更好的结果,因为它考虑了更多的输入像素信息。在放大图像时,效果与双线性插值类似,也会导致一定程度的模糊
-
bicubic 双三次插值: 速度较慢, 计算更复杂。比双线性插值更平滑,能更好地抑制锯齿和伪影。能在一定程度上保留图像细节,但仍然可能存在一些模糊。在高对比度边缘附近可能会出现轻微的振铃效应
-
bislerp 双二次曲面片: 试图在平滑度和细节保留之间取得更好的平衡。在一些情况下,可以产生比双三次插值更好的结果,特别是对于自然图像
Upscale Latent By
潜空间图像按系数放大
Latent From Batch
从一批潜空间图像中提取一个片段. batch_index 要提取的第一个潜空间图像的索引, length 要提取的潜空间图像数量
Repeat Latent Batch
重复潜空间图像批次, amount 重复次数
LatentBatch

将两组潜空间图像合并为一个批次
Rebatch Latents

拆分/合并潜空间图像批次
Latent Composite
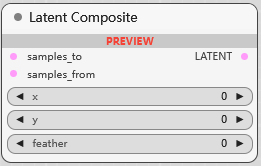
合并潜空间图像, 将 from 合并到 to, x/y 指定 from 坐标, feather 指定 to 羽化程度
LatentCompositeMasked
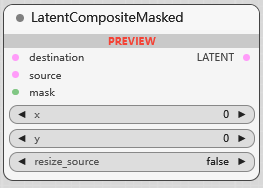
与上一个一样是合并, 将 source 合并到 destination, 可选的 mask 遮罩, 可以指定 source 要用于合并的部分, resize 选项选择是否调整 source 的尺寸以适应 destination
Rotate Latent
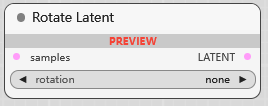
旋转潜空间图像, 90, 180, 270
Flip Latent
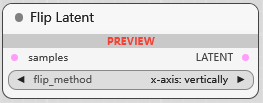
水平/垂直翻转潜空间图像
Crop Latent
裁剪潜空间图像, 指定图像宽/高, 坐标
LatentAdd
两个潜空间图像加合成一个新的潜空间图像
LatentSubtract

第一个潜空间图像中移除第二个潜空间图像的属性
LatentMultiply

潜空间图像特征按系数放大, 调整潜空间图像内特征的强度或大小
LatentInterpolate
潜空间图像插值, 按比例混合两个潜空间图像, 0 时是第一个潜空间图像, 1 时是第二个, 0-1 则按比例插值, 产生一个新的潜空间图像
LatentBatchSeedBehavior
潜空间图像批次随机化, 用于打乱批次索引
BETA LatentApplyOperation
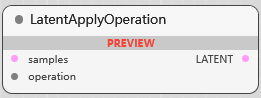
潜空间图像处理
BETA LatentApplyOperationCFG
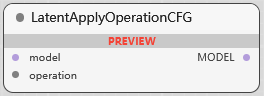
CFG 版处理
BETA LatentOperationTonemapReinhard
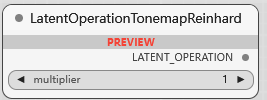
潜空间色调调节处理
BETA LatentOperationSharpen
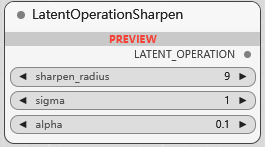
潜空间锐化处理, sharpen_radius 控制锐化影响的范围, sigma 控制锐化过程中高斯平滑的程度, alpha 控制锐化效果的强度
StableCascade_EmptyLatentImage
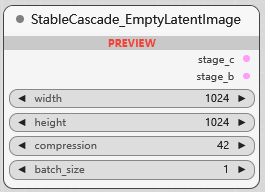
创建 StableCascade 模型空的潜空间图像, compression 压缩级别
StableCascade StageC VAEEncode

StableCascade 模型 VAE 编码
EmptyLatentAudio

创建空的潜空间音频
VAEEncodeAudio

音频 VAE 编码
VAEDecodeAudio

音频 VAE 解码
EmptySD3LatentImage
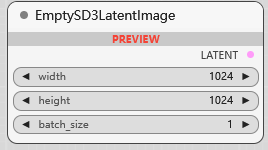
创建空的 SD3 潜空间图像
EmptyMochiLatentVideo

创建空的 Mochi 模型潜空间视频
EmptyLTXVLatentVideo

创建空的 LTXV 模型潜空间视频
图像节点
Save Image
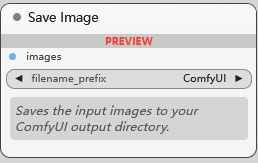
保存图像节点, 图像保存到 ComfyUI/output 下. 默认前缀是 ComfyUI, 后缀是 5 个数字, 如: ComfyUI_00001_.png
自定义保存图像文件夹/文件名:
-
自定义路径和文件名
例如
test/001, 则图像保存路径如ComfyUI/output/test/001_00001_.png -
使用日期命名:
日期表示法
yyyy:年份(4 位数字) yy:年份(2 位数字) MM:月(2 位数字) dd:天 (2 位数字) hh:小时(2 位数字) mm:分钟(2 位数字) ss:秒(2 位)例如
%date:yyMMdd%/%date:hh-mm-ss%, 则图像保存路径如ComfyUI\output\241210\15-22-22_00002_.png -
使用宽/高, 或节点小组件的值命名
%width% 宽, %height% 高
小组件值如:
%Load Checkpoint.ckpt_name%(节点标题) 或%CheckpointLoaderSimple.ckpt_name%(节点 S&R 名, 优先使用 S&R 名), 节点同名的需要重命名这样你可以将生成图像所使用的模型, 提示词, 种子, 步数等等, 都可以用作图片名
例如, 将正向提示词的
CLIP Text Encode (Prompt)命名为poCLIPTextEncode后,%date:yyyy-MM-dd%/%poCLIPTextEncode.text%_%width%x%height%_%KSampler.seed%_%Load Checkpoint.ckpt_name%则图像保存路径如:
"ComfyUI\output\2024-12-10\cat_512x512_457284464742973_majicmixRealistic_v7.safetensors_00001_.png"
Preview Image

预览图像
Load Image
加载图像
Upscale Image

图像放大, 放大算法 (这里只介绍 lanczos 算法, 其他在潜空间图像放大介绍过):
nearest-exact
bilinear
area
bicubic
lanczos
Lanczos 算法是一种高质量的图像放大算法,它通过使用 Lanczos 窗口对 sinc 函数进行加窗,在锐度、细节保留和平滑度之间取得了较好的平衡。虽然计算量较大,但它通常能够生成比其他插值算法更优质的放大图像
Upscale Image By
图像按系数放大
Upscale Image (using Model)
图像使用模型放大, 需要加载放大模型
Scale Image to Total Pixels
图像按像素放大, megapixels 图像的目标大小,以百万像素为单位。这决定了放大图像的总像素数
Invert Image
图像反转, 转换图像的颜色为互补色
Batch Images
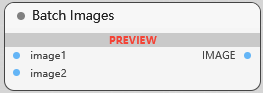
组合图像批次, 将两张图象组合成一个批次, 第二章图像的尺寸会自动重新调整以匹配第一张
Pad Image for Outpainting
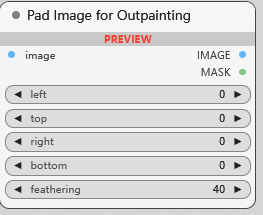
图像外补画板, 通过在图像周围添加填充来对图像进行外延处理, feathering, 羽化程度
Emptylmage

生成具有指定尺寸和颜色的空白图像. color, 使用十六进制值定义生成图像的颜色
Image Blend
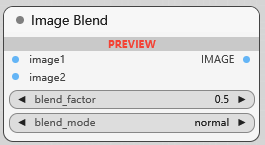
图像混合, blend_factor 第二张图像在混合中的权重. 混合模式:
normal
multiply
screen
overlay
soft_light
difference
正常、乘法、屏幕、叠加、柔光和差异模式,每种模式都产生独特的视觉效果
Image Blur
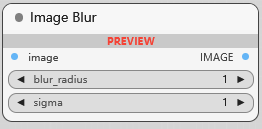
图像模糊, 对图像应用高斯模糊,允许软化边缘并减少细节和噪声. blur_radius模糊效果的半径, 更大的半径会导致更明显的模糊; sigma 控制模糊的扩散
Image Quantize
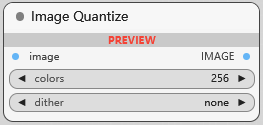
图像颜色量化, colors 指定将图像调色板减少到的颜色数量, 颜色数量较少将导致文件大小的明显减少,但也可能导致图像细节的损失; dither 抖动参数决定了在量化过程中要应用的抖动技术, 抖动技术:
none
floyd-steinberg
bayer-2
bayer-4
bayer-8
bayer-16
Image Sharpen
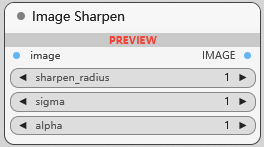
图像锐化, sigma 控制锐化效果的扩散, 较高的sigma值会在边缘产生更平滑的过渡,而较低的sigma使锐化更局部化, alpha 调整锐化效果的强度
ImageMorphology
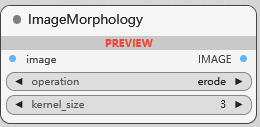
图像形态学操作, 基于形状的图像处理技术,常用于图像降噪、边缘检测、物体分割等.
operation 形态学操作的类型; kernel_size 核大小, 操作使用的基本结构元素.
操作类型:
-
Erode (腐蚀):
原理: 使用结构元素对图像进行“腐蚀”操作。如果结构元素覆盖的所有像素都与图像中的对应像素匹配,则输出像素保持不变;否则,输出像素被设置为背景值(通常为黑色)。
效果: 使图像中的亮区域(前景)收缩,细小的连接和噪声会被消除。可以去除小的噪点,分离小的物体。
比喻: 想象一下海岸线被海水侵蚀,陆地面积会缩小。
-
Dilate (膨胀):
原理: 使用结构元素对图像进行“膨胀”操作。如果结构元素覆盖的任何一个像素与图像中的对应像素匹配,则输出像素被设置为前景值(通常为白色)。
效果: 使图像中的亮区域(前景)扩张,可以填充小的空洞,连接断裂的区域。可以连接相邻的物体,填充小的空洞。
比喻: 想象一下陆地向海洋扩张,陆地面积会增大。
-
Open (开运算):
原理: 先对图像进行腐蚀,再进行膨胀。
效果: 可以去除小的亮区域(噪声),平滑物体的轮廓,同时保持较大的物体形状基本不变。
比喻: 想象一下用一个小刷子先刷掉小的凸起,再用刷子把凹陷填平。
-
Close (闭运算):
原理: 先对图像进行膨胀,再进行腐蚀。
效果: 可以填充物体内部的小空洞,平滑物体的轮廓,同时保持较大的物体形状基本不变。
比喻: 想象一下用一个小铲子先把凹陷填平,再把凸起铲平。
-
Gradient (形态学梯度):
原理: 计算图像的膨胀结果与腐蚀结果的差值。
效果: 可以提取物体的边缘。边缘的宽度由 kernel_size 决定。
比喻: 想象一下沿着物体的边缘画一条线。
-
Top Hat (顶帽):
原理: 计算图像的原始图像与开运算结果的差值。
效果: 可以提取比结构元素小的亮区域(例如,噪声或细节)。
比喻: 想象一下从原始地形中减去被平滑后的地形,剩下的就是突出的部分(小山峰)。
-
Bottom Hat (底帽):
原理: 计算图像的闭运算结果与原始图像的差值。
效果: 可以提取比结构元素小的暗区域(例如,孔洞或裂缝)。
比喻: 想象一下用被填平后的地形减去原始地形,剩下的就是凹陷的部分(小坑)
ImageCompositeMasked
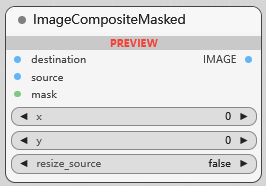
图像遮罩复合, 将源图像覆盖在目标图像上,在指定坐标处进行叠加,可选择调整大小和使用遮罩. 与潜空间遮罩复合类似.
Rebatch Images

重新分批图像批次
RepeatlmageBatch
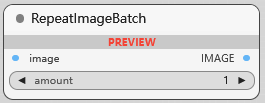
重复图像批次
ImageFromBatch
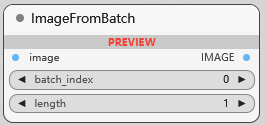
从一批图像中取一个片段
Canny
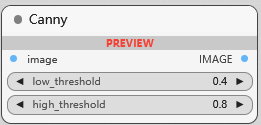
图像的边缘检测, low_threshold 阈值下限, 影响边缘检测的灵敏度, high_threshold 阈值上限, 影响边缘检测的选择性
Image Crop
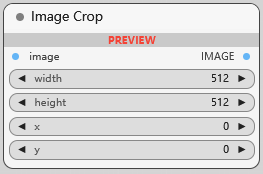
图片裁剪
SaveAnimatedWEBP
将一系列图像保存为动画 WEBP 文件. lossless 是否使用无损压缩, quality 压缩质量, method 压缩方法: 默认, 最快, 最慢
SaveAnimatedPNG
从一系列帧创建和保存动画PNG图像. compress_level 压缩级别
Webcam Capture

打开网络摄像头, capture_on_queue 参数控制摄像头捕获图像的时机,True 表示在节点执行时捕获,False 表示在工作流开始时捕获
蒙版
Load Image (as Mask)

加载图像作为蒙版, alpha 使用图像的 Alpha 通道 (透明度通道) 作为遮罩, red/green/blue 使用图像的红色/绿色/蓝色通道作为遮罩
Convert Mask to Image

遮罩转图像
Convert Image to Mask

图像转遮罩
ImageColorToMask

将彩色图像根据指定的颜色转换为遮罩
SolidMask

生成一个在所有维度上具有统一值的实心遮罩, 特别适用于进一步处理或作为更复杂遮罩操作的起点. value: 用于填充整个遮罩的统一值, 决定了遮罩的基本颜色或强度
InvertMask

反转遮罩
CropMask

裁剪遮罩
MaskComposite

遮罩合并, 合并操作:
-
multiply (相乘): 输出遮罩是两个输入遮罩对应像素值相乘的结果。重叠区域倾向于变暗(值变小)。
-
add (相加): 输出遮罩是两个输入遮罩对应像素值相加的结果。重叠区域倾向于变亮(值变大), 可能会饱和(值被限制为最大)。
-
subtract (相减): 输出遮罩是第一个输入遮罩减去第二个输入遮罩对应像素值的结果。重叠区域根据两者的差值变暗或者变亮。
-
and (与): 输出遮罩是两个输入遮罩对应像素值进行逻辑与操作的结果。只有当两者都为非零值时,输出才为非零,否则为零。重叠区域倾向于保留两者重叠的部分, 其他部分变为透明。
-
or (或): 输出遮罩是两个输入遮罩对应像素值进行逻辑或操作的结果。只要两者中有一个为非零值,输出就为非零。重叠区域倾向于只要有遮罩的部分都变为不透明。
-
xor (异或): 输出遮罩是两个输入遮罩对应像素值进行逻辑异或操作的结果。当两者值不同时,输出为非零,否则为零。重叠区域倾向于只保留两者只有一个遮罩的部分。
FeatherMask

羽化遮罩, 指定从上/下/左/右侧边缘开始应用羽化效果的距离
GrowMask
修改给定遮罩的大小,可以选择性地对角落应用渐缩效果. expand 确定遮罩修改的大小和方向, 正值导致遮罩扩展, 而负值导致收缩, tapered_corners 设置为 True 时, 修改过程中对遮罩的角落应用渐缩效果
ThresholdMask
按阈值转换遮罩, 较高的值包含较少的像素,较低的值包含更多的像素
Porter-Duff Image Composite
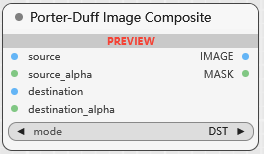
波特-达夫图像合成. 基于 Porter-Duff 合成规则对两张图像进行合成,其中一个图像作为前景 (Source, 通常表示为 SRC),另一个作为背景 (Destination, 通常表示为 DST)
合并模式 (A 和 B 分别表示前景和背景图像):
-
SRC : 只显示前景图像 (A)。
-
DST : 只显示背景图像 (B)。
-
SRC_OVER: 前景覆盖在背景上 (A over B),这是最常用的模式。
-
DST_OVER: 背景覆盖在前景上 (B over A)。
-
SRC_IN: 只显示前景中与背景重叠的部分 (A in B),且使用前景的不透明度。
-
DST_IN: 只显示背景中与前景重叠的部分 (B in A),且使用背景的不透明度。
-
SRC_OUT: 只显示前景中不与背景重叠的部分 (A out B)。
-
DST_OUT: 只显示背景中不与前景重叠的部分 (B out A)。
-
SRC_ATOP: 前景中与背景重叠的部分覆盖在背景上 (A atop B),其他部分不显示. 使用前景的不透明度。
-
DST_ATOP: 背景中与前景重叠的部分覆盖在前景上 (B atop A),其他部分不显示. 使用背景的不透明度。
-
XOR: 显示前景和背景中不重叠的部分 (A xor B)。
-
CLEAR: 清除所有内容,得到一个透明图像。
-
ADD: 将前景和背景的像素值相加。
-
MULTIPLY: 将前景和背景的像素值相乘。
-
SCREEN: 类似于“叠加”,但更亮一些。
-
OVERLAY: 根据背景的亮度,对前景进行“叠加”或“滤色”。
-
DARKEN: 选择前景和背景中较暗的像素。
-
LIGHTEN: 选择前景和背景中较亮的像素。
Split Image with Alpha

分离图像颜色和透明度
Join Image with Alpha
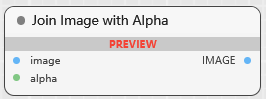
将图像与其对应的 Alpha 遮罩结合
测试功能 (暂不介绍)
BETA Latent Blend
BETA VAE Decode (Tiled)

BETA VAE Encode (Tiled)
BETA LoadLatent
BETA SaveLatent
BETA AddNoise
BETA Self-Attention Guidance

BETA PerpNegGuider

BETA PhotoMakerLoader
BETA PhotoMakerEncode
BETA CLIPTextEncodeControlnet
BETA StableCascade_SuperResolutionControlnet
BETA Differential Diffusion

BETA UNetSelfAttentionMultiply

BETA UNetCrossAttentionMultiply

BETA CLIPAttentionMultiply
BETA UNetTemporalAttentionMultiply

BETA SamplerEulerCFG++
BETA Extract and Save Lora
BETA TorchCompileModel
