内置节点 3
高级节点
Load CLIP

加载 CLIP 模型, CLIP 应用类型选择:
stable_diffusion: clip-l
stable_cascade: clip-g
sd3: t5/clip-g/clip-l
stable_audio: t5
mochi: t5
Itxv: t5
stable_diffusion
stable_cascade
sd3
stable_audio
mochi
Itxv
Load Diffusion Model
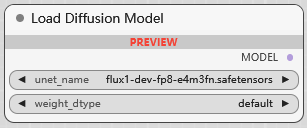
加载 UNET 模型, 权重类型:
default
fp8_e4m3fn
fp8_e4m3fn_fast
fp8_e5m2
-
default:
通常指的是模型的原始精度,大多数情况下是 FP32 (单精度浮点数) 或 FP16 (半精度浮点数)。
具体取决于模型在训练时使用的精度。
default 提供最高的数值精度,但内存占用也最大,计算速度相对较慢。
-
fp8_e4m3fn:
这是一种 8 位浮点数格式,具体来说是 E4M3FN 变体。
E4M3FN 指的是:
E4: 4 位指数 (Exponent)
M3: 3 位尾数 (Mantissa)
FN: 指示浮点数表示法,包括正负无穷和 NaN (Not a Number)。
fp8_e4m3fn 比 FP32 或 FP16 占用更少的内存,并且可以加速计算。
但是,由于精度降低,可能会引入一些数值误差,导致生成质量略微下降。
-
fp8_e4m3fn_fast:
这与 fp8_e4m3fn 相同,都是 E4M3FN 格式的 8 位浮点数。
_fast 后缀通常表示它使用了更快的硬件指令或算法来进行类型转换或计算,以牺牲一些潜在的精度为代价。
目标是在 fp8_e4m3fn 的基础上进一步提升速度。
-
fp8_e5m2:
这是另一种 8 位浮点数格式,具体来说是 E5M2 变体。
E5M2 指的是:
E5: 5 位指数 (Exponent)
M2: 2 位尾数 (Mantissa)
相比 fp8_e4m3fn,fp8_e5m2 拥有更大的指数范围,但尾数精度更低。
这使得 fp8_e5m2 能够表示更大范围的数值,但在表示精度上不如 fp8_e4m3fn。
在某些情况下,fp8_e5m2 可能更适合处理具有较大动态范围的模型权重。
DualCLIPLoader
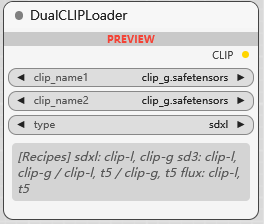
双 CLIP 加载器, 应用类型选择:
sdxl
sd3
flux
sdxl: clip-l, clip-g
sd3: clip-l, clip-g 或 clip-l, t5 或 clip-g, t5
flux: clip-l, t5
DiffusersLoader
已弃用
TripleCLIPLoader

三 CLIP 加载器, 适用于 SD3, 同时加载 clip-g, clip-l, t5
ConditioningZeroOut
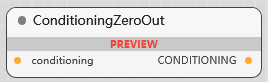
条件零化, 生成无条件信号
ConditioningSetTimestepRange
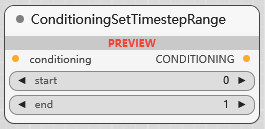
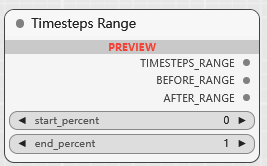
在特定的时间步范围内应用 conditioning, 更精细地控制 conditioning 在扩散过程的哪个阶段起作用
CLIPTextEncodeSDXLRefiner
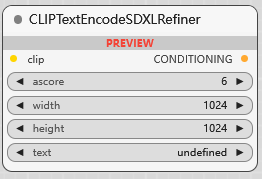
SDXL Refiner 模型文本编码, ascore 参数用于 Aesthetic Score (美学分数) 的条件控制, 它允许你引导模型生成更符合特定美学评分的图像
CLIPTextEncodeSDXL
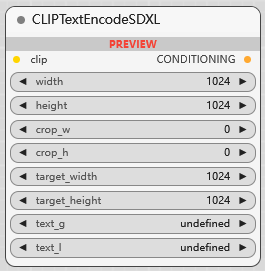
SDXL 文本编码:
width: 生成图像的目标宽度(以像素为单位)。
height: 生成图像的目标高度(以像素为单位)。
crop_w: 在编码 conditioning 之前,对内部生成的图像进行中心裁剪的宽度偏移量(可以为正或负)。通常设为0。
crop_h: 在编码 conditioning 之前,对内部生成的图像进行中心裁剪的高度偏移量(可以为正或负)。通常设为0。
target_width: 用于计算内部生成图像大小的宽度目标值,通常和width一致。
target_height: 用于计算内部生成图像大小的高度目标值,通常和height一致。
text_g: clip_g 编码的文本。
text_l: clip_l 编码的文本。
CLIPTextEncodeSD3
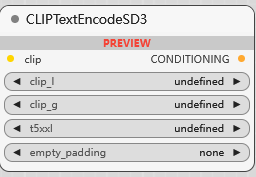
SD3 模型的文本编码:
clip_l: clip_l 编码的文本
clip_g: clip_g 编码的文本
t5xxl: t5xxl 编码的文本
empty_padding: 一个特殊的填充表示,用于在输入文本较短时进行填充,以适应模型对固定长度输入的需要
CLIPTextEncodeHunyuanDiT
HunyuanDiT 模型文本编码, bert/mt5xl 模型分别编码
CLIPTextEncodeFlux
flux 文本编码, guidance 调节引导强度,
FluxGuidance
条件转 flux 引导, 并调节引导强度
ModelMergeSimple
合并模型 1 和 2, 当 ratio 为 1 时, 保留 1, 0 时保留 2, 其他值按比例合并
ModelMergeBlocks
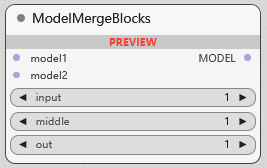
分层融合模型, 模型 2 的 输入层/中间层/输出层 按比例融合进 模型 1
ModelMergeSubtract
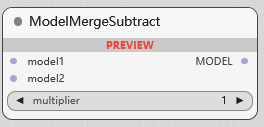
模型 1 减去 模型 2 进行融合, multiplier 减去的强度
ModelMergeAdd
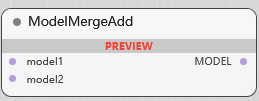
将 模型 2 添加到 模型 1 中
Save Checkpoint
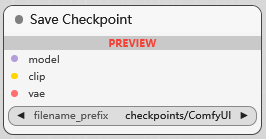
保存模型(可包含clip/vae)
CLIPMergeSimple
CLIP 合并
CLIPMergeSubtract
CLIP1 - CLIP2
CLIPMergeAdd
CLIP 2 加到 CLIP 1 中
CLIPSave
保存 CLIP
VAESave
保存 VAE
ModelSave
保存模型
ImageOnlyCheckpointSave
保存仅图像模型 (只能图生图的模型)
ModelMergeSD1
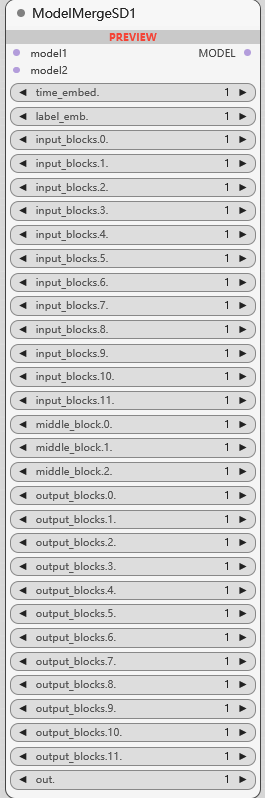
SD1 模型无缝集成到一个统一的框架中, 1 决定模型初始结构, 2 扩展模型能力:
time_embed: 调整模型中的时间嵌入
label_emb: 调整标签嵌入
input_blocks/middle_block/out_blocks: 输入层/中间层/输出层
out: 调整最终输出
ModelMergeSD2
同 SD1
ModelMergeSDXL
同 SD1
ModelMergeSD3_2B
SD3_2B 模型合并
ModelMergeAuraflow
Auraflow 模型合并
ModelMergeFlux1
Flux1 模型合并
ModelMergeSD35_Large
SD35_Large 模型合并
ModelMergeMochiPreview

MochiPreview 模型合并
ModelMergeLTXV
LTXV 模型合并
ModelSamplingDiscrete
模型采样离散, 修改模型的采样行为
eps
v_prediction
lcm
x0
ModelSamplingContinuousEDM
集成连续 EDM (基于能量的扩散模型) 采样技术来增强模型的采样能力:
v_prediction
edm_playground_v2.5
eps
ModelSamplingContinuousV
集成连续 V
ModelSamplingStableCascade
shift 调整采样分布, 调整 StableCascade 采样能力
ModelSamplingSD3
调整 SD3 的采样能力
ModelSamplingAuraFlow
调整 AuraFlow 的采样能力
ModelSamplingFlux

调整 Flux 的采样能力
RescaleCFG
按系数缩放 CFG 范围
ModelSamplingLTXV
调整 LTXV 的采样能力
TomePatchModel
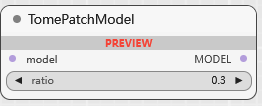
ratio: 调整模型注意力机制
FreeU

大幅提高扩散模型样本质量的方法, https://github.com/ChenyangSi/FreeU
推荐参数:
-
SD1.4: (will be updated soon)
b1: 1.3, b2: 1.4, s1: 0.9, s2: 0.2
-
SD1.5: (will be updated soon)
b1: 1.5, b2: 1.6, s1: 0.9, s2: 0.2
-
SD2.1
b1: 1.4, b2: 1.6, s1: 0.9, s2: 0.2
-
SDXL
b1: 1.3, b2: 1.4, s1: 0.9, s2: 0.2 SDXL results
-
推荐尝试参数范围
b1: 1 ≤ b1 ≤ 1.2
b2: 1.2 ≤ b2 ≤ 1.6
s1: s1 ≤ 1
s2: s2 ≤ 1
FreeU V2

https://github.com/WASasquatch/FreeU_Advanced
HyperTile
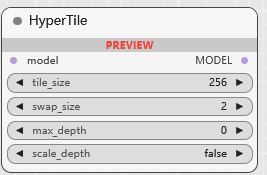
优化U-Net和VAE模型中的自我关注层的方法, https://github.com/tfernd/HyperTile
PatchModelAddDownscale (Kohya Deep Shrink)
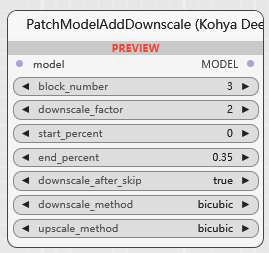
通过对特定块进行缩小和放大操作来修改模型,控制分辨率并优化性能:
-
block_number 区块号
此整数参数指定模型内将应用缩小操作的块号。默认值为 3,最小值为 1,最大值为 32。调整此参数允许您针对模型的特定层进行缩小。
-
downscale_factor 缩减因子
该浮点参数确定所选块将缩小的因子。默认值为 2.0,最小值为 0.1,最大值为 9.0。较高的缩小因子将更显着地降低分辨率。
-
start_percent 起始百分比
此浮点参数将缩小操作的起点定义为模型处理的百分比。默认值为 0.0,范围为 0.0 到 1.0。这使您可以控制模型执行期间开始缩小的时间。
-
end_percent 结束百分比
此浮点参数将缩小操作的结束点设置为模型处理的百分比。默认值为 0.35,范围为 0.0 到 1.0。此参数可帮助您定义缩小效果的持续时间。
-
downscale_after_skip 跳过后缩小规模
此布尔参数指示模型内的跳过连接后是否应发生缩小。默认值为 True。设置此参数可帮助您控制与跳过连接相关的精确缩小点。
-
downscale_method 缩小方法
该参数指定用于缩小尺寸的方法
bicubic nearest-exact bilinear area bislerp -
upscale_method 放大方法
该参数定义了缩小操作后用于放大的方法
PerturbedAttentionGuidance

扰动注意引导, 自校正采样, https://github.com/sunovivid/Perturbed-Attention-Guidance
SaveAudio
保存音频
LoadAudio

加载音频
PreviewAudio
预览音频
SavelmageWebsocket

保存图像以用 api 获取
以下测试功能暂不介绍:
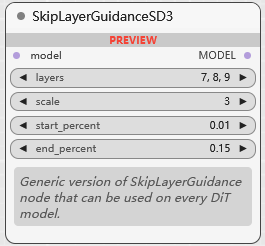
BETA SkipLayerGuidanceSD3
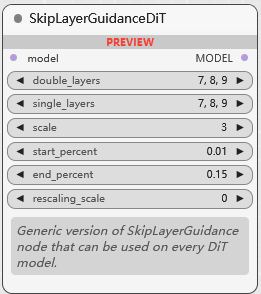
BETA SkipLayerGuidanceDiT
BETA Create Hook LoRA

BETA Create Hook LoRA (MO)

BETA Create Hook Model as LoRA
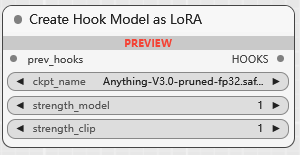
BETA Create Hook Model as LoRA (MO)
BETA Set Hook Keyframes

BETA Create Hook Keyframe

BETA Create Hook Keyframes Interp.

BETA Create Hook Keyframes From Floats

BETA Combine Hooks [2]

BETA Combine Hooks [4]

BETA Combine Hooks [8]

BETA Cond Set Props
BETA Cond Set Props Combine
BETA Cond Set Default Combine

BETA Cond Pair Set Props

BETA Cond Pair Set Props Combine
BETA Cond Pair Set Default Combine
BETA Cond Pair Combine

BETA Set CLIP Hooks
BETA Timesteps Range